오늘은 ①문자열 웹 크롤링 후 ②엑셀 파일에 저장하는 것을 남겨보고자 한다.
파이썬에서 엑셀을 제어할 수 있는 라이브러리는 종류가 많은데, 오늘은 openpyxl 을 사용하였다.
크롤링을 할 때, 지난번 구글 및 네이버 이미지 크롤링 때처럼 Selenium 을 사용할 수도 있지만, 오늘은 BeautifulSoup 을 사용하였다. 마지막으로 웹 크롤링에는 간단하게 HTML/CSS 보는 법이 필요하다.
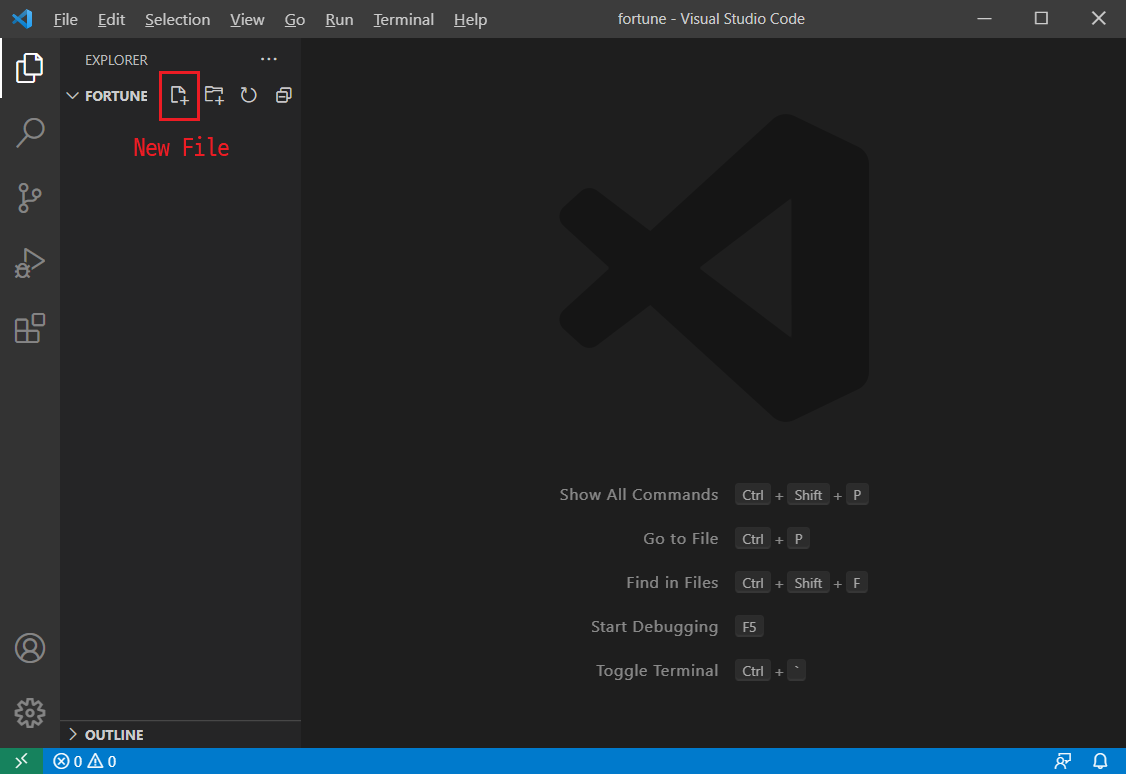
1) VSCode(Visual Studio Code)를 실행한 후, [ File > Open Folder... > 저장될 폴더 선택 ] 한다. 그리고 그 폴더에 파이썬 파일(파일명.py)을 하나 만든다. (fortune.py 라고 만들어 보겠다.)
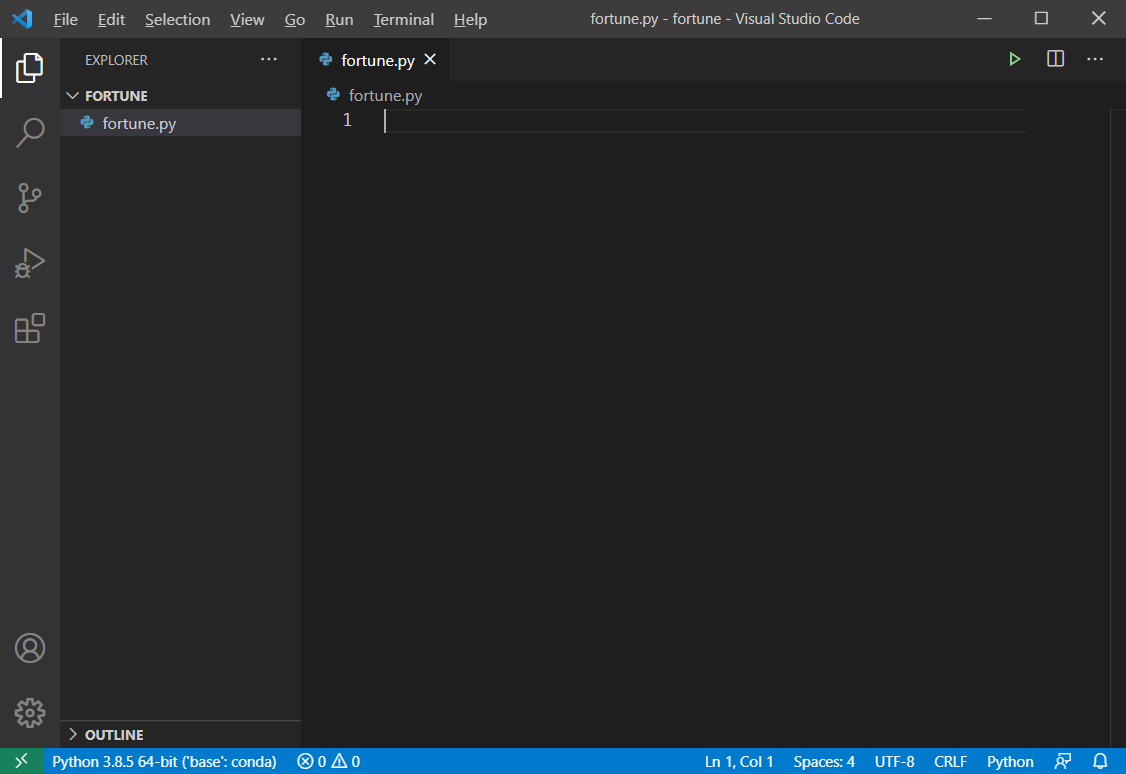
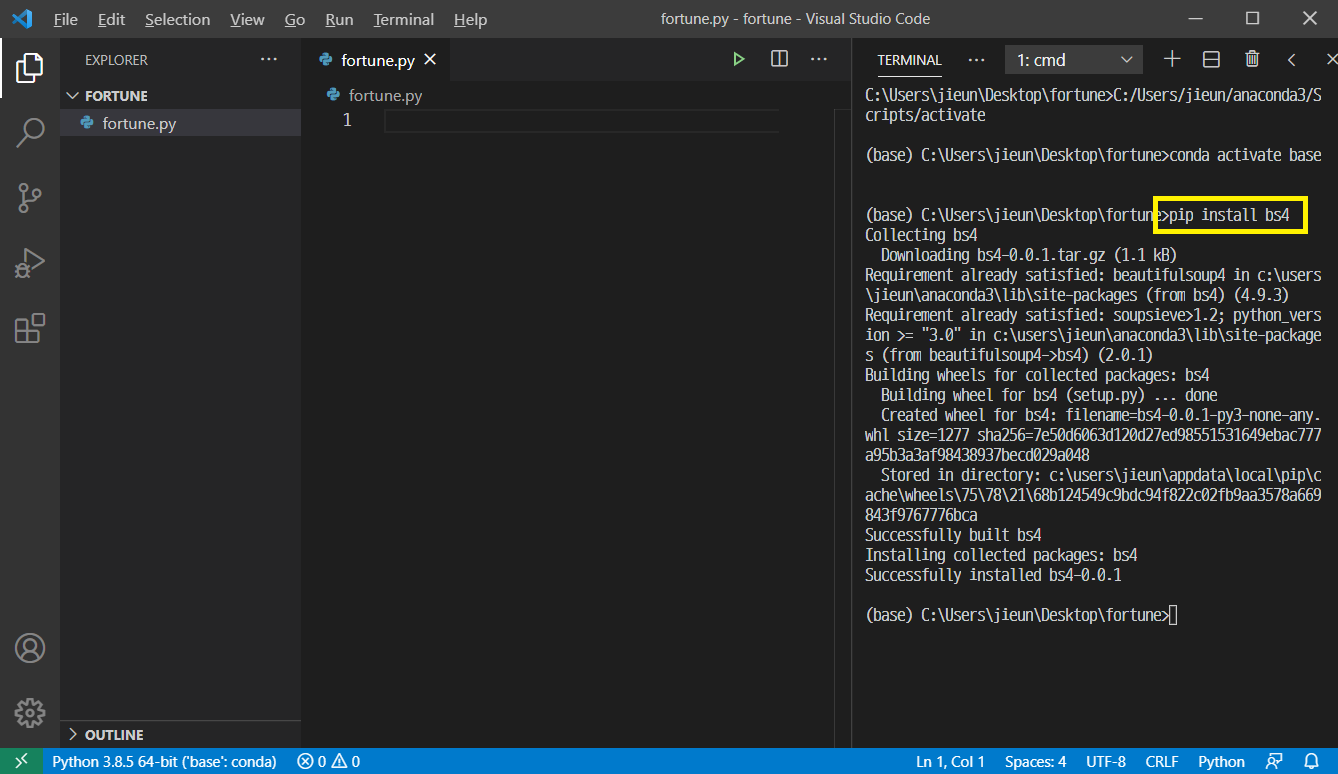
터미널 창을 열고(Ctrl + J), BeautifulSoup 과 openpyxl 라이브러리를 설치해준다.
- BeautifulSoup 설치 방법 : pip install bs4 + Enter
- openpyxl 설치 방법 : pip install openpyxl + Enter
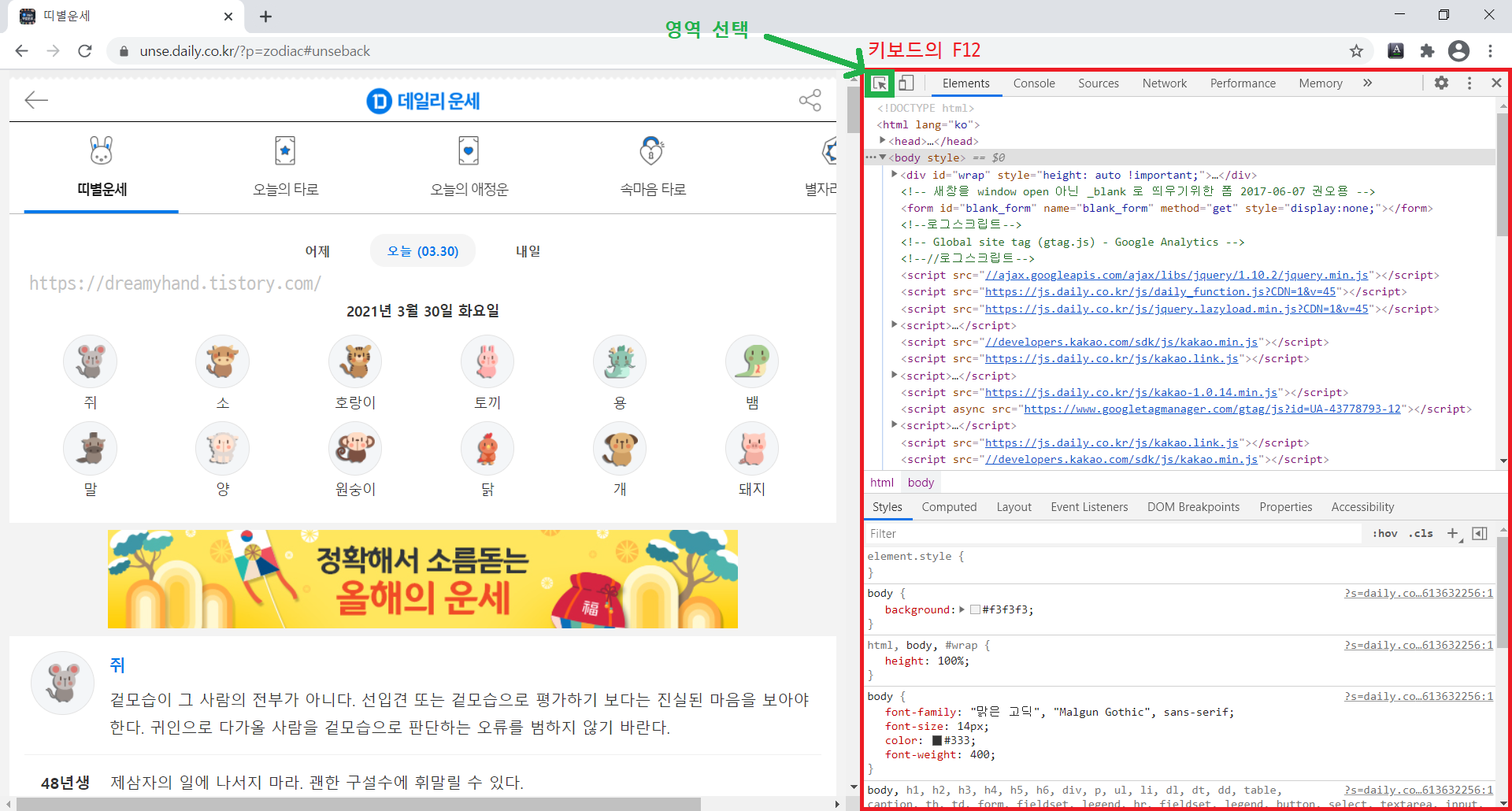
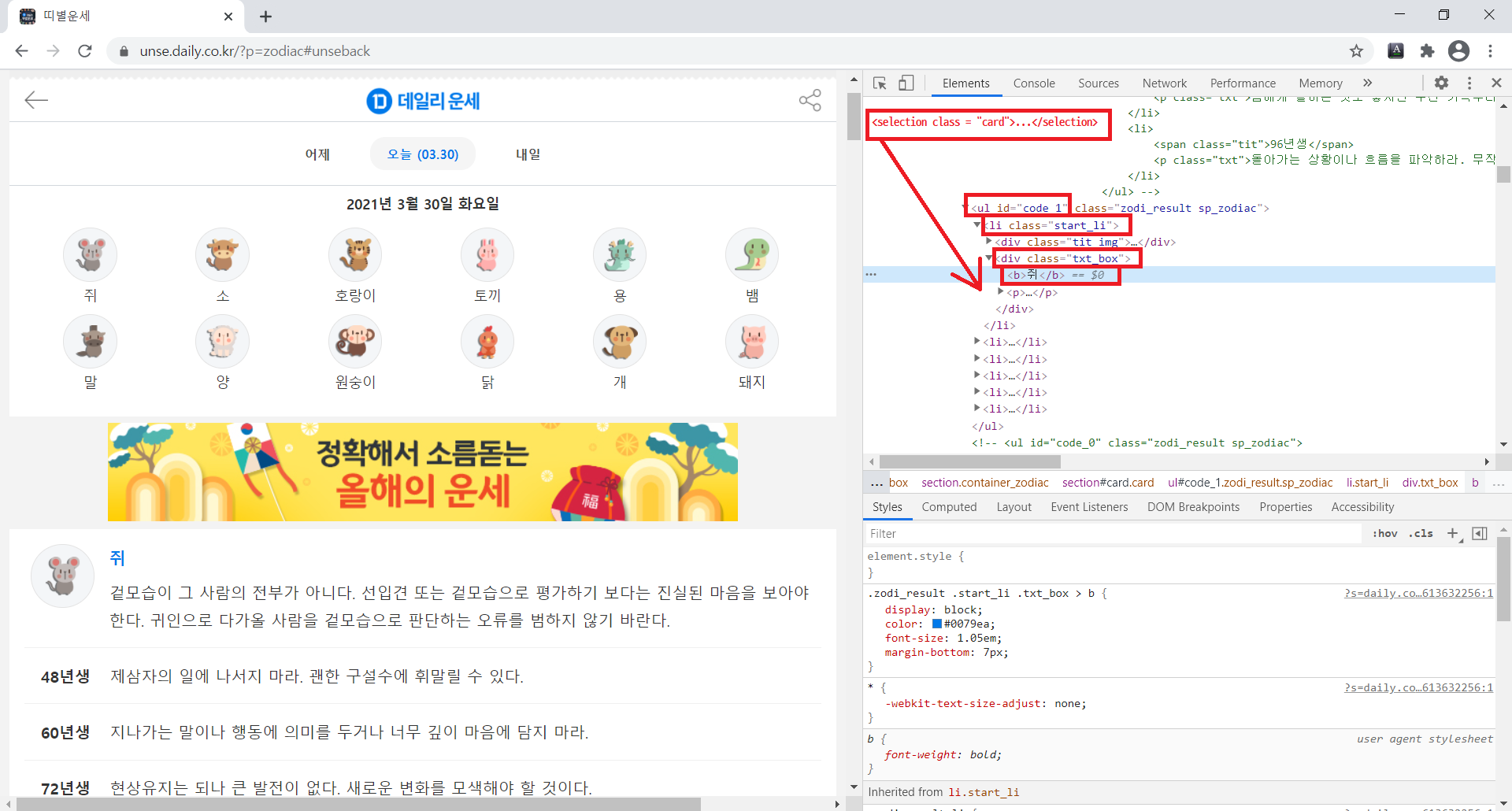
2) 크롬(Chrome)에서 데일리 운세 사이트( unse.daily.co.kr/?p=zodiac )로 접속하여 웹 페이지 HTML 구성을 살펴본다( 키보드의 F12 > Elements ).
그리고 초록색으로 표시한 곳을 클릭하고 웹페이지에 마우스를 움직여보면 영역별로, 구역별로 짜여진 HTML 코드를 확인할 수 있다.
HTML/CSS 에는 부모, 자식, 형제, 자손 선택자, 자식 선택자, 인접 형제 선택자 등이 있다.
쉽게 말해 상속을 하는데 부모 > 자식 > 자손 이런 식이다.
html > body > p
div > h1 > span
body 은 html 의 자식 요소이고, p 의 부모 요소이다. p 는 html 의 자손 요소이다. 다음 줄도 마찬가지다.
같은 부모를 가지고 있는 요소들은 서로 형제 관계에 있다.
형제 관계에 있는 요소 중 바로 뒤에 이어 나오는 요소를 인접해 있다고 한다.
영상이 아니라 글로 쓰다보니 설명이 미흡한데, 영역 선택을 해보면 '띠별운세 결과' 부분의 최상위 클래스명은 <selection class="card"> ... </selection> 임을 알 수 있다. 그리고 스크롤을 내려보면, [ 최상위 > 상위 > 하위1 > 하위2 ... ] 이런 구조임을 알 수 있다.

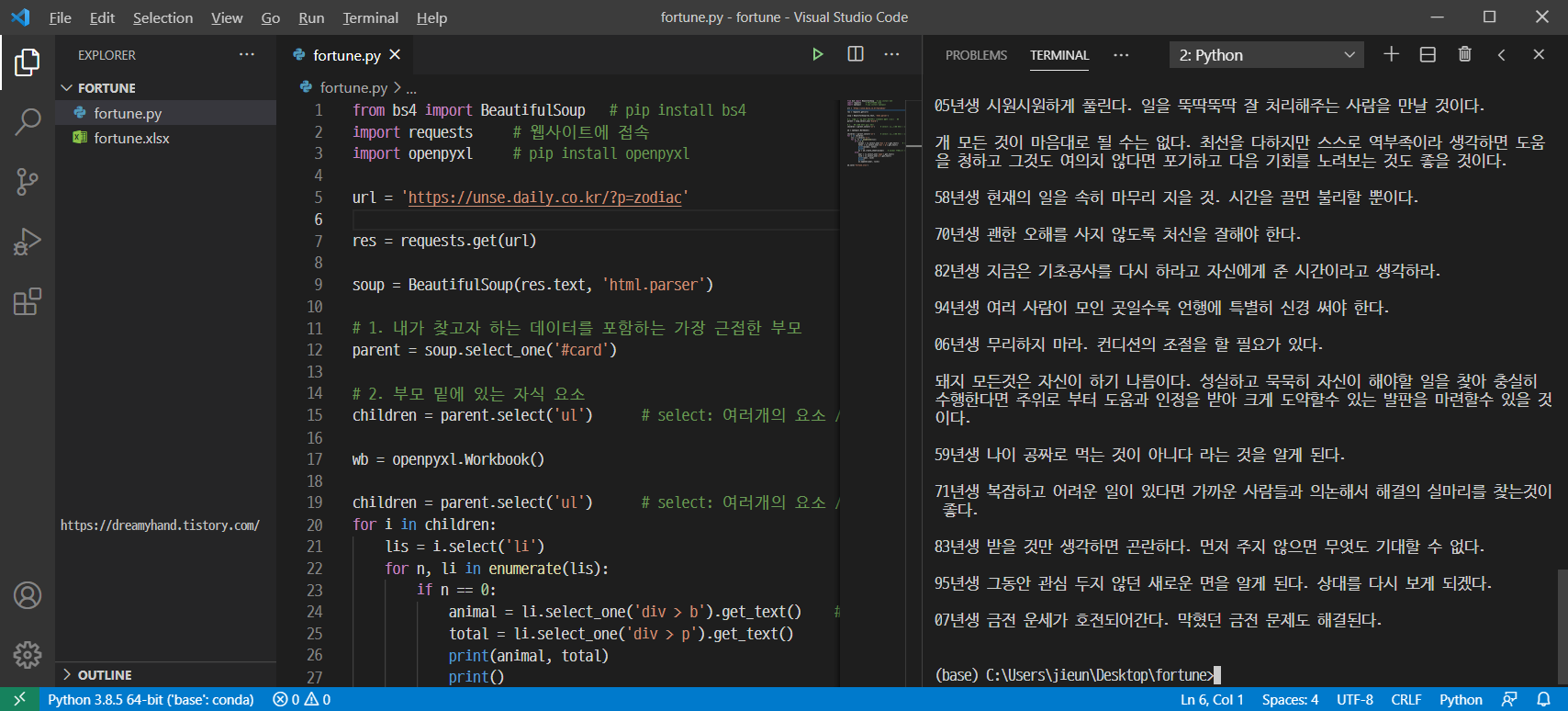
이쯤에서 코드를 먼저 공개하는 것이 이해가 빠를 것이다. (단, 항상 내가 올리는 코드보다 더 효율적인 코드는 얼마든지 있을 수 있다.)
* 라이브러리를 사용하기 위해서는 먼저 import 를 해주어야 한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
from bs4 import BeautifulSoup # pip install bs4
import requests # 웹사이트에 접속
import openpyxl # pip install openpyxl
url = 'https://unse.daily.co.kr/?p=zodiac'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'html.parser')
# 1. 내가 찾고자 하는 데이터를 포함하는 가장 근접한 부모
parent = soup.select_one('#card')
# 2. 부모 밑에 있는 자식 요소
children = parent.select('ul') # select: 여러개의 요소 / select_one: 가장 첫번째 요소
wb = openpyxl.Workbook()
children = parent.select('ul') # select: 여러개의 요소 / select_one: 가장 첫번째 요소
for i in children:
lis = i.select('li')
for n, li in enumerate(lis):
if n == 0:
animal = li.select_one('div > b').get_text() # 태그 중 텍스트 추출
total = li.select_one('div > p').get_text()
print(animal, total)
print()
ws = wb.create_sheet(animal) # animal 이름으로 시트 생성
ws.append([total])
else:
year = li.select_one('span').get_text()
luck = li.select_one('p').get_text()
print(year, luck)
print()
ws.append([year, luck])
wb.save('fortune.xlsx')
|
cs |
엑셀에 띠별로 각기 다른 시트에 저장하는 코드를 사용했는데, 그 부분은 아래를 참고하면 된다.
< openpyxl 샘플 코드 > : Google 에 openpyxl 이라고 검색하면 나온다.
from openpyxl import Workbook
wb = Workbook()
# grab the active worksheet
ws = wb.active
# Data can be assigned directly to cells
ws['A1'] = 42
# Rows can also be appended
ws.append([1, 2, 3])
# Python types will automatically be converted
import datetime
ws['A2'] = datetime.datetime.now()
# Save the file
wb.save("sample.xlsx")
우선 파이썬 결과창을 보면 이렇게 문자열이 잘 크롤링 된 것을 볼 수 있다.
옆 폴더에 보면, 엑셀 파일도 잘 생성 되었다. (fortune.xlsx)
엑셀 파일은 파이썬 안에서는 열 수 없고, 탐색기에서 열어주면 된다. 결과창은 다음과 같다.
첫번째 시트는 기본값이다. 띠별로 시트가 잘 생성되었고, 시트별로 '띠별 총운 + 생년별 운세' 가 제대로 담긴 것을 볼 수 있다.
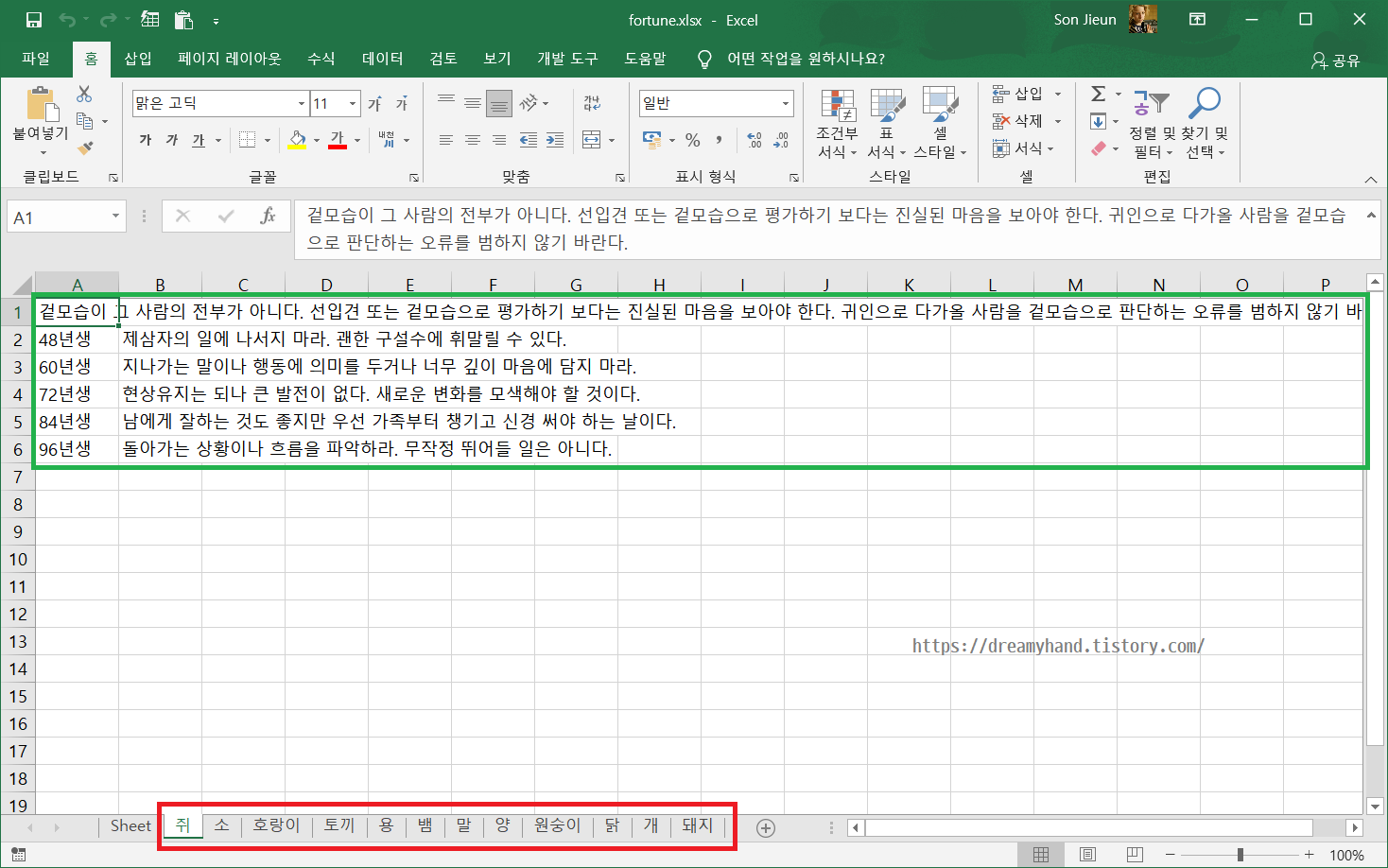
이렇게 웹 페이지의 정보들을 내가 원하는 정해진 형태로 모은 다음, 분석을 할 수 있을 것이다.
오늘 해본 것은 매우 단순한 것이지만, 공개된 공공데이터 등으로 응용을 해본다면 의미있는 일을 할 수 있을 것이다.
'Python & SQL > Python Practice' 카테고리의 다른 글
| 파이썬 실행 파일 만들기 (convert .py to .exe) (2) | 2021.04.06 |
|---|---|
| 기상청 공공데이터로 내 생일 기온 변화 그래프 그리기(feat. 주피터 노트북) (0) | 2021.03.31 |
| 파이썬 자연 언어 처리(Natural Language Processing, NLP) 맛보기 (0) | 2021.03.29 |
| 파이썬 네이버 이미지 크롤링(Python Naver Image Crawling) (0) | 2021.03.24 |
| 파이썬 구글 이미지 크롤링(Python Google Image Crawling) (0) | 2021.03.23 |