텍스트 데이터는 구조화되어 있지 않기 때문에 분석이 어렵다고 느껴질 수 있다.
하지만 적절한 전처리와 벡터화 기법을 활용하면, 단순한 상품명만으로도 충분히 의미 있는 패턴을 발견할 수 있다.
이번 포스팅에서는 수업 중 연습문제로 내주신 상품명을 기반으로 유사한 제품들을 자동으로 묶는 '군집화(clustering)' 과정을 단계별로 정리해보고자 한다.
특히 TF-IDF와 KMeans를 활용하여 제품 카테고리가 어떻게 자연스럽게 분리되는지 확인해본다.
데이터 로드 및 기본 탐색
# 먼저 UCI에서 제공하는 상품 데이터를 불러온다. 이 데이터에는 다양한 상품명(Product Title)이 포함되어 있다.
import pandas as pd
df = pd.read_csv('pricerunner_aggregate.csv')
print(df['Product Title'].head())
# 데이터를 확인한 뒤, 상품명이 없는 경우는 분석에 사용할 수 없으므로 제거한다.
df = df.dropna(subset=['Product Title'])
텍스트 전처리
상품명은 다양한 기호와 대소문자가 섞여 있기 때문에, 모델이 이해하기 쉬운 형태로 정제하는 과정이 필요하다.
핵심은 소문자로 변환, 알파벳과 숫자를 제외한 문자 제거이다.
import re
def clean_text(text):
text = text.lower()
text = re.sub(r'[^a-z0-9 ]', '', text)
return text
df['clean_title'] = df['Product Title'].apply(clean_text)
print(df[['Product Title', 'clean_title']].head())
이 과정을 거치면 "Apple iPhone 14(128GB)!" 같은 텍스트가 "apple iphone 14 128gb" 형태로 정리된다.
TF-IDF 벡터화
이제 텍스트를 숫자로 변환한다. 단순히 단어 개수를 세는 방식이 아니라, 각 단어의 중요도를 반영하는 TF-IDF를 사용한다.
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(stop_words='english', max_features=1000)
X = vectorizer.fit_transform(df['clean_title'])
print("TF-IDF shape:", X.shape)
여기서 중요한 점은 다음과 같다.
- stop_words='english': 의미 없는 단어 제거
- max_features=1000: 중요한 단어만 사용
즉, 모델이 핵심 단어에 집중하도록 만드는 과정이다.
최적 클러스터 수 찾기 (Silhouette Score)
군집화에서 가장 중요한 질문은 "몇 개로 나눌 것인가"이다. 이를 위해 Silhouette Score를 사용한다.
Silhouette Score는 -1 부터 1 사이의 값을 가지며, 값이 클수록 군집이 잘 나뉘었다는 의미이다.
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
scores = []
K_range = range(2, 11)
for k in K_range:
kmeans = KMeans(n_clusters=k, random_state=42)
labels = kmeans.fit_predict(X)
score = silhouette_score(X, labels)
scores.append(score)
print(f"K={k}, Silhouette Score={score:.4f}")
이 결과를 시각화하면 최적의 K를 직관적으로 확인할 수 있다.
import matplotlib.pyplot as plt
plt.figure()
plt.plot(K_range, scores, marker='o')
plt.xlabel('Number of Clusters (K)')
plt.ylabel('Silhouette Score')
plt.title('Silhouette Score vs K')
plt.show()
보통 가장 높은 점수를 가지는 K를 선택하면 된다.
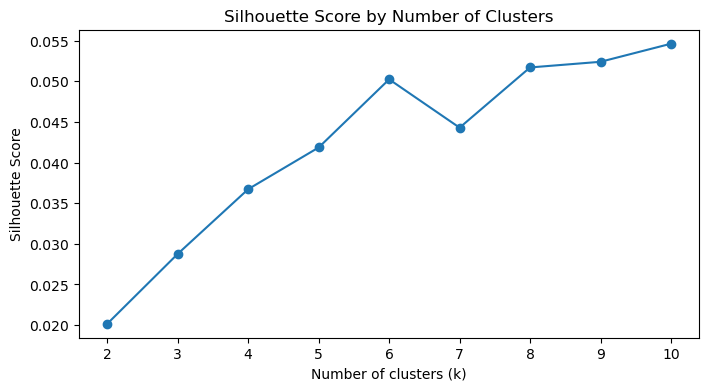
KMeans 클러스터링 수행
선택한 K값을 기반으로 실제 군집화를 수행한다.
import numpy as np
optimal_k = K_range[np.argmax(scores)]
print("Optimal K:", optimal_k)
kmeans = KMeans(n_clusters=optimal_k, random_state=42)
df['cluster'] = kmeans.fit_predict(X)
print(df[['clean_title', 'cluster']].head())
이제 각 상품은 특정 클러스터에 속하게 된다.
PCA를 활용한 2차원 시각화
고차원 벡터는 눈으로 확인하기 어렵기 때문에, PCA를 사용해 2차원으로 축소하여 시각화한다.
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X.toarray())
plt.figure()
for cluster in range(optimal_k):
plt.scatter( X_pca[df['cluster'] == cluster, 0],
X_pca[df['cluster'] == cluster, 1],
label=f'Cluster {cluster}'
)
plt.xlabel('PCA 1')
plt.ylabel('PCA 2')
plt.title('PCA Visualization of Clusters')
plt.legend()
plt.show()
이 그래프를 보면 비슷한 상품들이 자연스럽게 모여 있는 것을 확인할 수 있다.

결과 해석
실제로 군집 결과를 살펴보면 다음과 같은 패턴이 나타난다.
- 스마트폰 관련 제품
- 노트북 및 컴퓨터
- 오디오 기기
- 가전제품
즉, 모델이 별도의 라벨 없이도 상품 카테고리를 자동으로 구분하고 있는 것이다.
한 단계 더 나아가기
* 클러스터링 라벨링: 각 클러스터에 의미를 부여하면 추천시스템, 상품 분류 자동화 같은 실제 서비스로 확장할 수 있다.
마무리
이번 글에서는 상품명이라는 간단한 텍스트 데이터만으로도 의미있는 군집을 만들어내는 과정을 살펴보았다.
핵심은 3가지 이다.
1) 텍스트 전처리로 노이즈 제거
2) TF-IDF로 단어 중요도 반영
3) KMeans로 유사한 상품 자동 그룹화
이 흐름은 영화 리뷰, 뉴스 기사, 고객 피드백 등 다양한 텍스트 데이터에도 그대로 적용할 수 있다.
'ML & DL' 카테고리의 다른 글
| [ML] 스마트폰 센서 데이터로 사용자 행동 분류하기: HAR 다중분류 실습 (0) | 2026.04.05 |
|---|---|
| 머신러닝을 한 단계 더 이해하기 (0) | 2026.03.29 |
| 머신러닝 성능을 바꾸는 핵심 요소 (0) | 2026.03.29 |
| 지도학습 핵심 개념과 대표 알고리즘 (0) | 2026.03.29 |
| 머신러닝의 기본 흐름 이해하기: 데이터부터 첫 모델까지 (0) | 2026.03.29 |